PyMC linear regression part 3: predicting average height
This is the next post in a series of linear regression posts using PyMC3. This series has been inspired by my reading of Statistical Rethinking. Part 1 was dedicated to setting up the problem and understanding the package’s objects. Part 2 was about interpreting the posterior distribution. In this entry, I’ll be using the posterior distribution to make predictions. Specifically, I’ll make the distinction between predicting average height which has its own uncertainty, and actual height. I’ll cover predictions of average height here.
The first few pieces of code will replicate the previous posts to get us to where we want to be.
import arviz as az
import matplotlib.pyplot as plt
import numpy as np
import os
import pandas as pd
import pymc3 as pm
import scipy.stats as stats
import seaborn as sns
%load_ext nb_black
%config InlineBackend.figure_format = 'retina'
%load_ext watermark
RANDOM_SEED = 8927
np.random.seed(RANDOM_SEED)
az.style.use("arviz-darkgrid")
Here again is the question that motivated the series of posts.
The weights listed below were recorded in the !Kung census, but heights were not recorded for these individuals. Provide predicted heights and 89% compatibility intervals for each of these individuals. That is, fill in the table below, using model-based predictions.
| Individual | weight | expected height | 89% interval |
|---|---|---|---|
| 1 | 45 | ||
| 2 | 40 | ||
| 3 | 65 | ||
| 4 | 31 |
d = pd.read_csv("../data/a_input/Howell1.csv", sep=";", header=0)
d2 = d[d.age >= 18] # filter to get only adults
Setting up the variables, producing model and trace objects
# Get the average weight as part of the model definition
xbar = d2.weight.mean()
with pm.Model() as heights_model:
# Priors are variables a, b, sigma
# using pm.Normal is a way to represent the stochastic relationship the left has to right side of equation
a = pm.Normal("a", mu=178, sd=20)
b = pm.Lognormal("b", mu=0, sd=1)
sigma = pm.Uniform("sigma", 0, 50)
# This is a linear model (not really a prior or likelihood?)
# Data included here (d2.weight, which is observed)
# Mu is deterministic, but a and b are stochastic
mu = a + b * (d2.weight - xbar)
# Likelihood is height variable, which is also observed (data included here, d2.height))
# Height is dependent on deterministic and stochastic variables
height = pm.Normal("height", mu=mu, sd=sigma, observed=d2.height)
# The next lines is doing the fitting and sampling all at once.
# I'll use the return_inferencedata=False flag
# I'll use the progressbar flag to minimize output
trace_m2 = pm.sample(1000, tune=1000, return_inferencedata=False, progressbar=False)
Auto-assigning NUTS sampler...
INFO:pymc3:Auto-assigning NUTS sampler...
Initializing NUTS using jitter+adapt_diag...
INFO:pymc3:Initializing NUTS using jitter+adapt_diag...
Multiprocess sampling (4 chains in 4 jobs)
INFO:pymc3:Multiprocess sampling (4 chains in 4 jobs)
NUTS: [sigma, b, a]
INFO:pymc3:NUTS: [sigma, b, a]
Sampling 4 chains for 1_000 tune and 1_000 draw iterations (4_000 + 4_000 draws total) took 11 seconds.
INFO:pymc3:Sampling 4 chains for 1_000 tune and 1_000 draw iterations (4_000 + 4_000 draws total) took 11 seconds.
trace_m2_df = pm.trace_to_dataframe(trace_m2)
Here again are some summary statistics of the posterior distribution.
az.rcParams["stats.hdi_prob"] = 0.89 # sets default credible interval used by arviz
az.summary(trace_m2, round_to=3, kind="stats")
/Users/blacar/opt/anaconda3/envs/stats_rethinking/lib/python3.8/site-packages/arviz/data/io_pymc3.py:88: FutureWarning: Using `from_pymc3` without the model will be deprecated in a future release. Not using the model will return less accurate and less useful results. Make sure you use the model argument or call from_pymc3 within a model context.
warnings.warn(
| mean | sd | hdi_5.5% | hdi_94.5% | |
|---|---|---|---|---|
| a | 154.602 | 0.267 | 154.152 | 154.996 |
| b | 0.903 | 0.042 | 0.834 | 0.969 |
| sigma | 5.106 | 0.197 | 4.802 | 5.430 |
# Get the covariance matrix.
trace_m2_df.cov().round(3)
| a | b | sigma | |
|---|---|---|---|
| a | 0.071 | -0.000 | 0.000 |
| b | -0.000 | 0.002 | -0.000 |
| sigma | 0.000 | -0.000 | 0.039 |
The correlation matrix can show how changing one parameter affects another.
trace_m2_df.corr()
| a | b | sigma | |
|---|---|---|---|
| a | 1.000000 | -0.004523 | 0.000751 |
| b | -0.004523 | 1.000000 | -0.011835 |
| sigma | 0.000751 | -0.011835 | 1.000000 |
Making predictions for average height ($\mu_i$)
Now that we have a good grasp of the data, we can make posterior predictions. Functionally, what we are doing is taking into account the probability distributions of each parameter (alpha, beta, sigma) when making the prediction.
However, it was not intuitive to me to see how to carry this out mechanically using pymc. Let’s walk through this step-by-step since there are different ways we can capture uncertainty.
One thing that I had some trouble grasping initially was the distinction in these two equations:
$\text{height}_i$ ~ Normal($\mu_i, \sigma$)
$\mu_i = \alpha + \beta(x_i - \bar{x})$
The first line is actual height, that incorporates the uncertainty of all parameters. The second line is average height. We can make predictions for both. Note that $\sigma$ is not represented but $\alpha$ and $\beta$ are both vectors so $\mu_i$ will also be a vector for a single weight value (or a matrix when looking at all weight values, see below). As stated above, we’ll focus on average height in this post.
In the next few plots, we are only considering plausible mean lines that can be generated with posterior distribution alpha and beta values while ignoring sigma. Here again is the trace_m2 object’s returned parameters (showing only the head of the dataframe). When we are predicting the mean for a given weight, it is helpful to remember that there is uncertainty for the mean itself.
trace_m2_df.head()
| a | b | sigma | |
|---|---|---|---|
| 0 | 154.363232 | 0.878117 | 5.149980 |
| 1 | 155.100196 | 0.899341 | 5.166454 |
| 2 | 154.226905 | 0.920709 | 5.049191 |
| 3 | 154.226905 | 0.920709 | 5.049191 |
| 4 | 154.614243 | 0.872827 | 5.043696 |
We can generate credibility intervals for the range of weight values using an arviz function. This puts bounds on the plausible mean line. Note how this code omits sigma.
# compute the hpdi for a range of weight values
cred_intervals = np.array(
[
az.hdi(
np.array(trace_m2_df.loc[:, "a"])
+ np.array(trace_m2_df.loc[:, "b"]) * (x - xbar)
)
for x in np.linspace(30, 65) # This is inputting a range of weight values.
]
)
# Take a look at credibility intervals
cred_intervals[0:5, :]
array([[139.91398663, 142.10746662],
[140.61586835, 142.72290189],
[141.31055931, 143.33144088],
[141.98464947, 143.92085427],
[142.67405724, 144.52814949]])
We can represent uncertainty in two ways in the figure down below. In the left plot, we will use a combination of $\alpha$ and $\beta$ samples to produce a bunch of lines from the posterior distribution. On the right, we are plotting with the credibility interval.
f, (ax1, ax2) = plt.subplots(1, 2, figsize=(12, 5))
# ax1 plot --------------------------------------------
# Plotting the data as a scatter plot
ax1.scatter(d2["weight"], d2["height"], alpha=0.5)
# Plotting mean lines using the first 50 sampled values for alpha and beta parameters
# note that sigma is not used
for i in range(50):
ax1.plot(
d2["weight"],
trace_m2_df["a"][i] + trace_m2_df["b"][i] * (d2["weight"] - xbar),
color="gray",
linewidth=0.2,
linestyle="dashed",
)
# Plotting the 50th for labeling purposes
ax1.plot(
d2["weight"],
trace_m2_df["a"][i] + trace_m2_df["b"][i] * (d2["weight"] - xbar),
color="gray",
linewidth=0.2,
linestyle="dashed",
label=r"a line for each of 100 randomly $\alpha$ and $\beta$ sampled values",
)
# Plotting the overall mean line
ax1.plot(
d2["weight"],
trace_m2["a"].mean() + trace_m2["b"].mean() * (d2["weight"] - xbar),
label="posterior mean line",
color="orange",
)
ax1.set_xlabel("weight")
ax1.set_ylabel("height")
ax1.legend(fontsize=11)
# ax2 plot --------------------------------------------
# Plotting the data as a scatter plot
ax2.scatter(d2["weight"], d2["height"], alpha=0.5)
ax2.fill_between(
np.linspace(30, 65),
cred_intervals[:, 0],
cred_intervals[:, 1],
alpha=0.4,
color="gray",
label="89% CI",
)
# Plotting the overall mean line
ax2.plot(
d2["weight"],
trace_m2["a"].mean() + trace_m2["b"].mean() * (d2["weight"] - xbar),
label="posterior mean line",
color="orange",
)
ax2.set_xlabel("weight")
ax2.set_ylabel("height")
ax2.legend(fontsize=11)
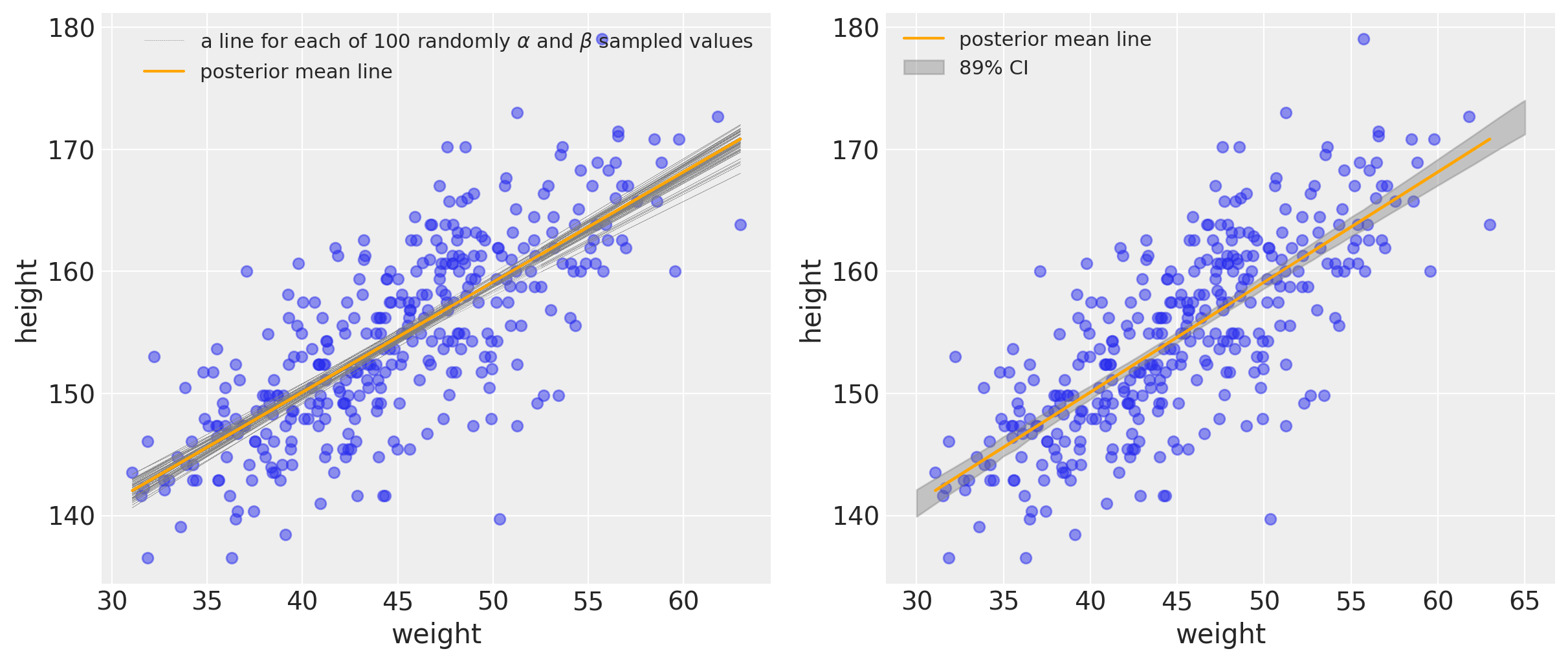
It’s important to remember that the orange line drawn represents the posterior mean line. It is the most plausible line, but it’s helpful to keep in mind that there’s uncertainty and other lines (gray) are plausible (albeit with lower probability).
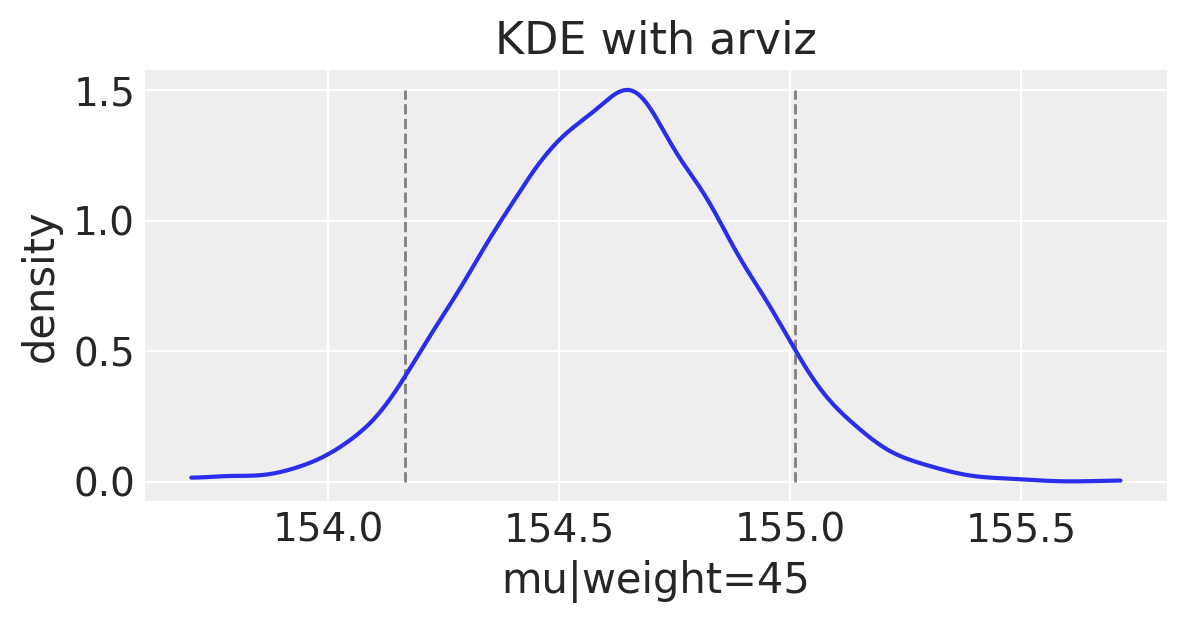
Understanding $\mu_i$ uncertainty at a single weight value
It might still be hard to see why we’d have uncertainty around a mean value. Let’s take only one weight, 45 kg. We can use the formula for our line and simply plug in the value of 45 for $x_i$. We will get back a vector of predicted means since $\alpha$ and $\beta$ are vectors. Again, note how $\sigma$ from our posterior distribution is still not used in this equation.
mu_at_45 = trace_m2_df["a"] + trace_m2_df["b"] * (45 - xbar)
mu_at_45
0 154.371587
1 155.108753
2 154.235666
3 154.235666
4 154.622548
...
3995 154.848588
3996 154.247808
3997 154.608258
3998 154.342976
3999 154.589418
Length: 4000, dtype: float64
We can plot the uncertainty around this single weight value.
# Get 89% compatibility interval
az.hdi(np.array(mu_at_45))
array([154.16661059, 155.01021454])
f, ax1 = plt.subplots(1, 1, figsize=(6, 3))
az.plot_kde(mu_at_45, ax=ax1)
ax1.set_title("KDE with arviz")
ax1.set_ylabel("density")
ax1.set_xlabel("mu|weight=45")
ax1.vlines(
az.hdi(np.array(mu_at_45)),
ymin=0,
ymax=1.5,
color="gray",
linestyle="dashed",
linewidth=1,
)
<matplotlib.collections.LineCollection at 0x7fecb04d5460>
Understanding $\mu_i$ uncertainty for a range weight values
Now let’s take a look at a range of weight values.
This is taken from the repo: “We are doing manually, in the book is done using the link function. In the book on code 4.58 the following operations are performed manually.”
# Input a range of weight values
weight_seq = np.arange(25, 71)
# Given that we have a lot of samples we can use less of them for plotting
# I just decided to use them all
# trace_m_thinned = trace_m2_df[::10]
# This is generating a matrix where the predicted mu values will be kept
# Each weight value will be its own row
mu_pred = np.zeros((len(weight_seq), len(trace_m2_df)))
# Fill out the matrix in this loop
for i, w in enumerate(weight_seq):
mu_pred[i] = trace_m2_df["a"] + trace_m2_df["b"] * (w - d2["weight"].mean())
The line for mu_pred can use further explanation. Unlike the example above where mu was a vector when evaluating at had for a single weight value, we will now return a matrix. (While I didn’t explicitly think to use this, this Stack Overflow link explains how MCMC uses multiple chains.)
df_mu_pred = pd.DataFrame(mu_pred, index=weight_seq)
df_mu_pred.index.name = "weight"
df_mu_pred.head()
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | ... | 3990 | 3991 | 3992 | 3993 | 3994 | 3995 | 3996 | 3997 | 3998 | 3999 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| weight | |||||||||||||||||||||
| 25 | 136.809256 | 137.121926 | 135.821484 | 135.821484 | 137.166000 | 135.657218 | 135.657218 | 135.657218 | 137.010733 | 137.442018 | ... | 136.315442 | 136.682549 | 137.083692 | 137.219905 | 135.234508 | 137.367422 | 136.002073 | 136.432719 | 136.817518 | 135.816661 |
| 26 | 137.687372 | 138.021267 | 136.742193 | 136.742193 | 138.038827 | 136.601131 | 136.601131 | 136.601131 | 137.900697 | 138.304255 | ... | 137.221021 | 137.580689 | 137.961734 | 138.091173 | 136.175118 | 138.241480 | 136.914360 | 137.341496 | 137.693791 | 136.755299 |
| 27 | 138.565489 | 138.920609 | 137.662903 | 137.662903 | 138.911655 | 137.545044 | 137.545044 | 137.545044 | 138.790662 | 139.166491 | ... | 138.126600 | 138.478828 | 138.839776 | 138.962441 | 137.115727 | 139.115539 | 137.826647 | 138.250273 | 138.570064 | 137.693937 |
| 28 | 139.443605 | 139.819950 | 138.583612 | 138.583612 | 139.784482 | 138.488957 | 138.488957 | 138.488957 | 139.680627 | 140.028727 | ... | 139.032180 | 139.376967 | 139.717819 | 139.833710 | 138.056337 | 139.989597 | 138.738933 | 139.159050 | 139.446337 | 138.632575 |
| 29 | 140.321722 | 140.719291 | 139.504321 | 139.504321 | 140.657310 | 139.432870 | 139.432870 | 139.432870 | 140.570591 | 140.890963 | ... | 139.937759 | 140.275107 | 140.595861 | 140.704978 | 138.996946 | 140.863655 | 139.651220 | 140.067827 | 140.322609 | 139.571212 |
5 rows × 4000 columns
f, axes = plt.subplots(2, 3, figsize=(12, 6))
# equally spaced weights weights in the weight range
arb_weights = np.linspace(25, 70, 6)
for arb_weight, ax in zip(arb_weights, axes.flat):
comp_interval = az.hdi(np.array(df_mu_pred.loc[arb_weight]))
legend_label = "CI range: {0:0.2f}".format(np.diff(comp_interval)[0])
az.plot_kde(df_mu_pred.loc[arb_weight], ax=ax)
ax.set_title("mu|weight=%i" % arb_weight + "\n" + legend_label)
# ax.legend() # cleaner to put as the title
if ax.is_first_col():
ax.set_ylabel("density")
if ax.is_last_row():
ax.set_xlabel("average height")
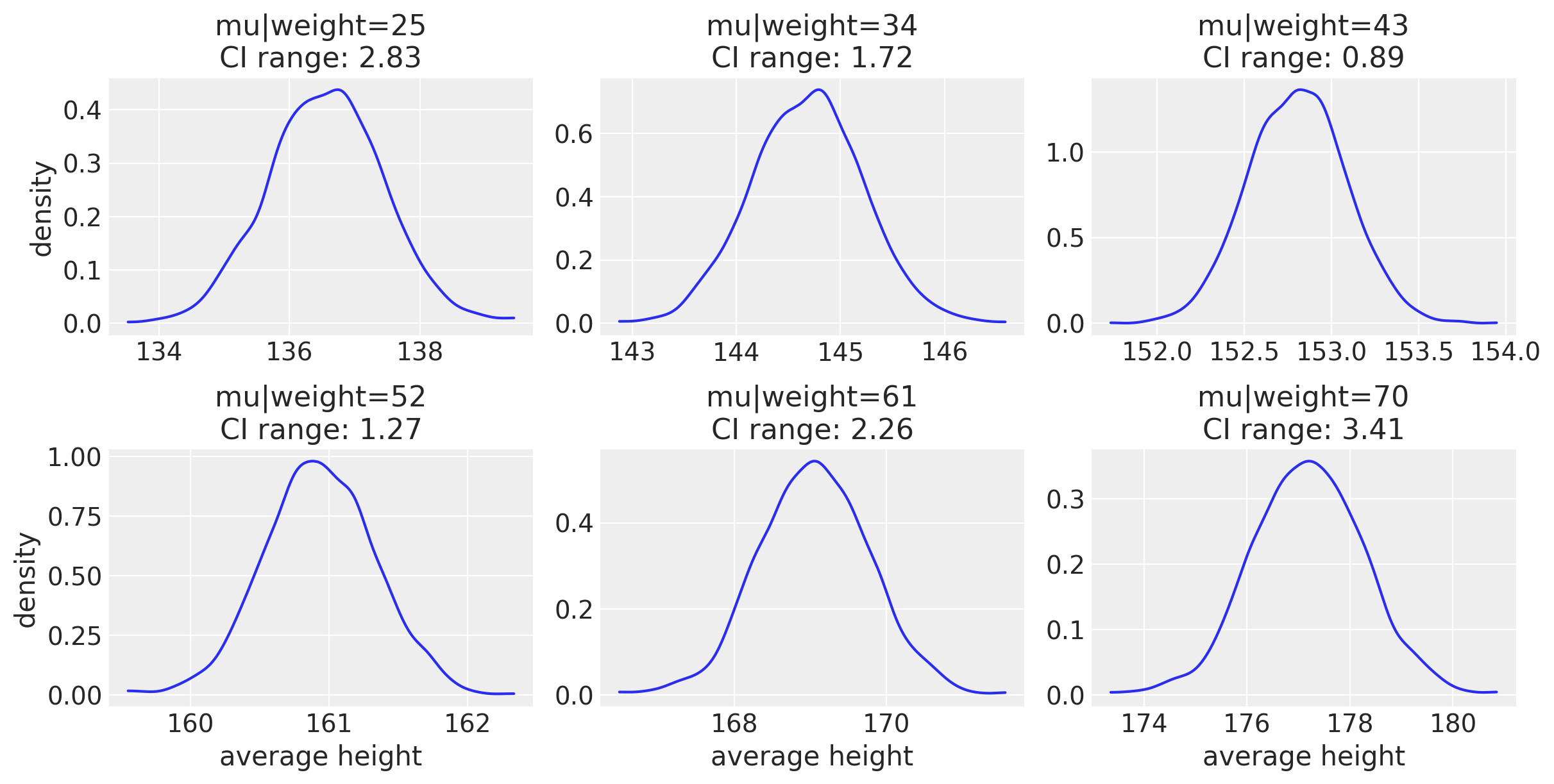
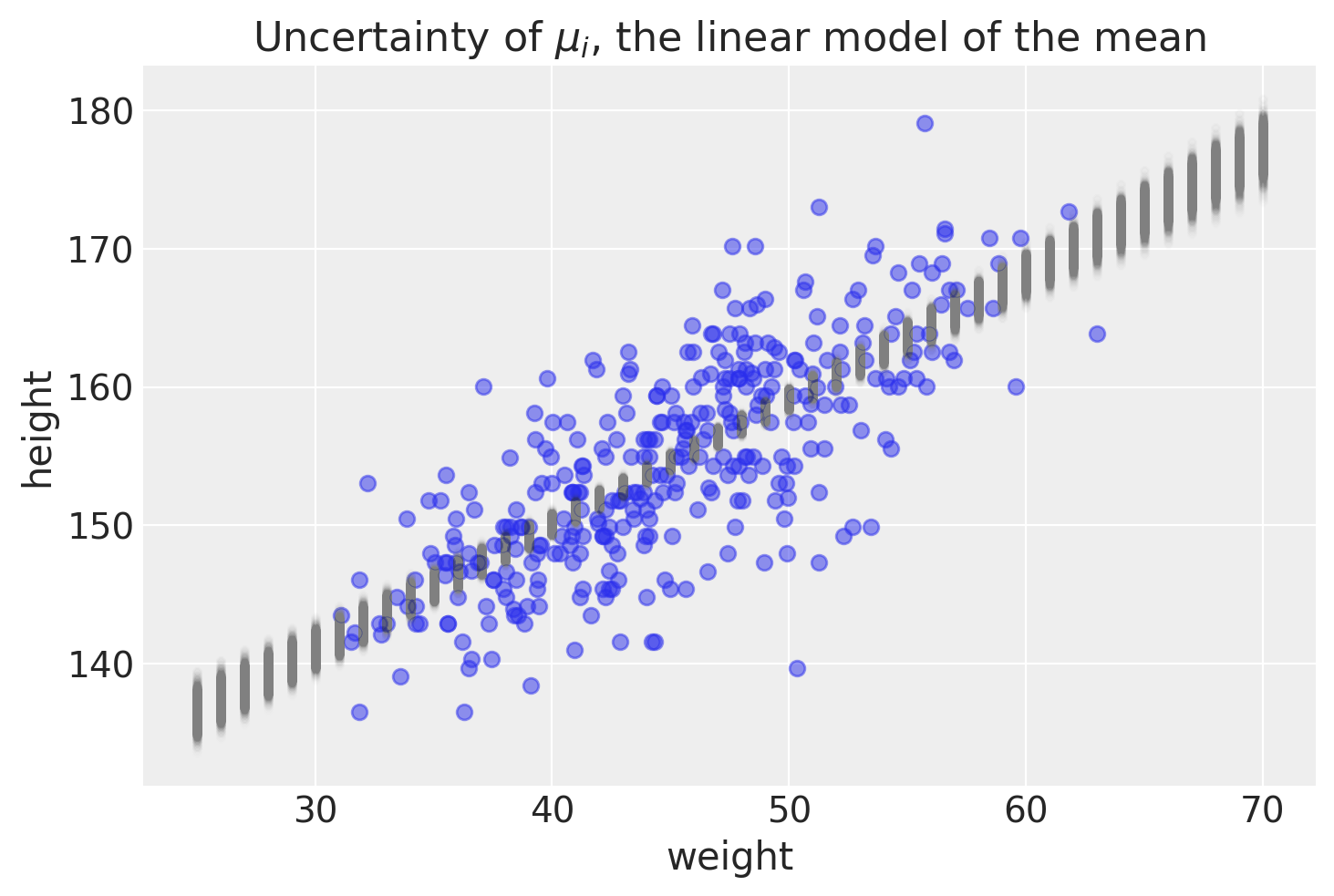
This is another way of looking at the variability for average height. The compatibility interval range (CI range) is showing how bigger the CI is when looking at either end of the weight range. Here is a more intuitive way of showing this, with the data points in blue.
# Plotting the data as a scatter plot
plt.scatter(d2["weight"], d2["height"], alpha=0.5)
plt.plot(weight_seq, mu_pred, "C0.", color="gray", alpha=0.005)
plt.xlabel("weight")
plt.ylabel("height")
plt.title(r"Uncertainty of $\mu_i$, the linear model of the mean")
Text(0.5, 1.0, 'Uncertainty of $\\mu_i$, the linear model of the mean')
Summary
The purpose of this post was to show how to make predictions on average height using pymc. We used our posterior distribution to make many different regression lines. We plotted the uncertainties of average height around individual weights to appreciate this point. One thing that I have stressed is making a distinction between average height versus actual height. The last figure highlights how making predictions on average height would lead to over-confidence in where a new point may lie. In the next post, we will use the posterior distribution to make predictions on actual height.
Appendix: Environment and system parameters
%watermark -n -u -v -iv -w
Last updated: Sat May 15 2021
Python implementation: CPython
Python version : 3.8.6
IPython version : 7.20.0
seaborn : 0.11.1
pymc3 : 3.11.0
arviz : 0.11.1
matplotlib: 3.3.4
pandas : 1.2.1
json : 2.0.9
scipy : 1.6.0
numpy : 1.20.1
Watermark: 2.1.0