Running models forwards and backwards
The value of simulations is highighted by Dr. McElreath throughout his textbook and by van de Schoot and colleagues. I didn’t entirely appreciate its value until I implemented this myself. I started by reviewing some materials, then I went down a rabbit hole, where one question naturally branched into other questions. I’ll talk about simulations in multiple posts and how model running forwards and backwards can help with understanding.
{kind=link}
{kind=link}
We’ll start simple, with a weighted coin example. Then in later posts, we’ll move into simple linear regression, then multiple linear regression and thinking from a causal perspective. As most of my recent posts have been inspired by my learning of Bayesian inference, much credit goes to Dr. McElreath’s Statistical Rethinking, its associated pymc repo, and friends on the Discord server. Colleagues at UCSF who are experts in simulations and causal models have also been a great source.
Let’s get started using our weighted coin example!
import arviz as az
import matplotlib.pyplot as plt
import numpy as np
import os
import pandas as pd
import pymc3 as pm
from scipy import stats
import statsmodels.api as sm
import seaborn as sns
sns.set_context("talk")
%load_ext nb_black
%config InlineBackend.figure_format = 'retina'
%load_ext watermark
RANDOM_SEED = 8927
np.random.seed(RANDOM_SEED)
az.style.use("arviz-darkgrid")
az.rcParams["stats.hdi_prob"] = 0.89 # sets default credible interval used by arviz
Running models forwards and backwards
We can input parameters to generate data. Or we can start from data, come up with a model to infer a parameter. When most people do statistics, they’re doing the latter. But running a model in both directions can help us understand things more deeply.
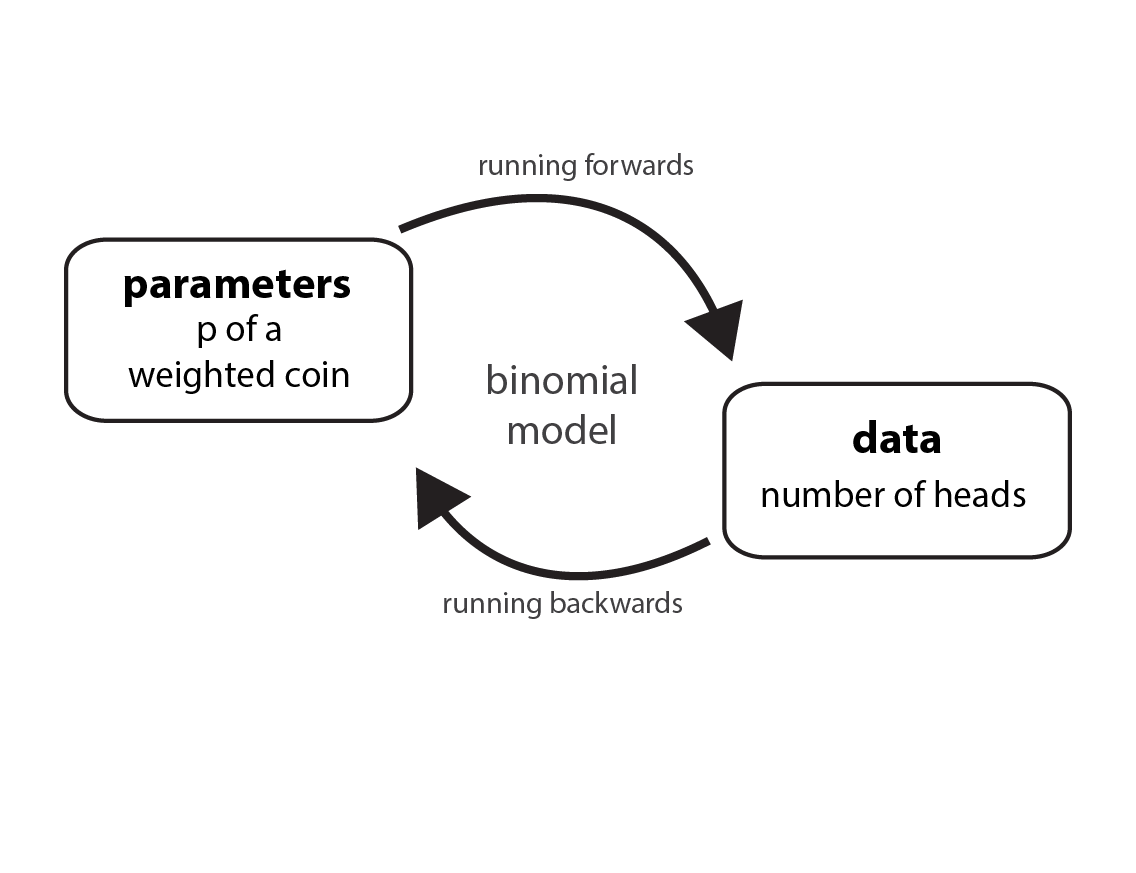
Let’s pretend we have a weighted coin. (We’ll use this in place of McElreath’s globe tossing example.) In many problems, we’re asked to deduce the true proportion that the coin comes up heads (or tails). This would be parameter estimation or what McElreath calls “running a model backwards”. A parameter is typically unobserved in contrast to data, which we can observe. We can count the number of heads after a known number of tosses. But for simulation (running a model forwards), we input a known parameter (how weighted the coin is) and generate data.
In our simulation, let’s say that the true proportion the coin comes up heads is 0.7. Since each coin toss is independent of the other, these are conditions for a binomial distribution. We’ll illustrate simulations using scipy.stats and inference using pymc. I’ll also show how to do a simulation using pymc alone but I think using the scipy.stats module has more flexibility.
Running forwards: simulation to get data
Let’s imagine we do two coin flips. The possibilities after three tosses ($n$=2) is to observe 0 heads (H), 1 H, or 2 H. The number of observed heads is assigned $k$. Formally, the model equation with the known parameters will look like this.
\[H \sim \text{Binomial}(n=2, p=0.7)\]It can be read as “the number of heads we will observe is binomially distributed after two tosses of a coin, with true known proportion of heads of 0.7”. We can get the probability mass function (PMF) for this distribution like this.
# k = 0, 1, or 2 heads
stats.binom.pmf(k=range(3), n=2, p=0.7)
array([0.09, 0.42, 0.49])
This means that, after two coin flips, we expect to observe 0 heads with 9% probability, 1 head with 42% probability, and 2 heads with 49% probability. These three possibilities sum to 100%. We can’t get more hits on water ($k$) than the number of tosses ($n$). This is made clear if we try to input a value of $k$ that is $n$. (We’ll do an explicit construction of a list of k values.)
stats.binom.pmf(k=[0, 1, 2, 3], n=2, p=0.7)
array([0.09, 0.42, 0.49, 0. ])
We don’t get an error, we simply get a probability of zero when $k > n$. Now let’s simulate.
We can use stats.binom.rvs to input parameters and generate data. Let’s do multiple trials, which is parameterized by size. To be clear, each trial means we’re doing two tosses and recording the number of heads in that trial. We’ll repeat this until we have 10 total trials.
# Use rvs to make dummy observations
stats.binom.rvs(n=2, p=0.7, size=10)
array([2, 2, 1, 1, 1, 2, 2, 2, 2, 1])
If you keep executing this cell, you’ll get a new set of values for observed W. We can also generate a high number of trials by simply making size large. We’ll do 10,000 trials.
dummy_h = stats.binom.rvs(n=2, p=0.7, size=10 ** 5)
dummy_h
array([2, 2, 1, ..., 1, 1, 2])
And from here, we can see how well the proportion of samples for each water value generated by the simulation matches the proportions determined analytically (using stats.binom.pmf).
# Wrap the list in a series so I can use `value_counts`
pd.Series(dummy_h).value_counts() / 10 ** 5
2 0.48837
1 0.42089
0 0.09074
dtype: float64
The numbers are pretty close to our PMF we calculated above.
Running backwards: inference to estimate the parameter
Now let’s run the model backwards with pymc starting with the data that we generated from running the model forward. This might seem like a silly exercise since the purpose of inference is to estimate an unknown parameter. But the point of this exercise is to see how the two directions of model running are connected.
Here is our model equation.
\(H \sim \text{Binomial}(n=2, p)\)
\(p \sim \text{Beta}(\alpha=2, \beta=2)\)
We can read this as “the number of heads we will observe is binomially distributed after two tosses and some unknown parameter p.” We have to give $p$ some plausible prior distribution. Since $p$ should be between 0 and 1, a beta distribution is a good choice. I wrote about the beta distribution in a prior post here.
I choice beta to be parameterized as (2,2) since it is fairly conservative, with most of the mass suggesting it is a fair coin. You’ll see the shape of this below, when we put it with the posterior. We can get the posterior in the following code. There is a closed form solution where we can get the posterior analytically. The following is a way to get it with MCMC. While using MCMC is overkill for this problem, it is applicable with more complicated models.
# Generate observed data
dummy_h = stats.binom.rvs(n=2, p=0.7, size=10)
# Infer the parameter
with pm.Model() as m1:
# prior
p = pm.Beta("p", alpha=2, beta=2)
# likelihood with unknown parameter p, observed dummy_h
H = pm.Binomial("H", n=2, p=p, observed=dummy_h)
# posterior
trace_m1 = pm.sample(
draws=1000, random_seed=19, return_inferencedata=True, progressbar=False
)
Auto-assigning NUTS sampler...
Initializing NUTS using jitter+adapt_diag...
Multiprocess sampling (4 chains in 4 jobs)
NUTS: [p]
Sampling 4 chains for 1_000 tune and 1_000 draw iterations (4_000 + 4_000 draws total) took 12 seconds.
Let’s plot the prior and posterior for $p$ together.
a = 2
b = 2
f, ax1 = plt.subplots(figsize=(12, 6))
# known parameter to generate data
ax1.axvline(
0.7, lw=1, color="red", linestyle="dashed", label="known p to generate data"
)
# prior
x = np.linspace(stats.beta.ppf(0.00, a, b), stats.beta.ppf(1.00, a, b), 100)
prior_label = "prior, beta(" + str(a) + ", " + str(b) + ")"
ax1.plot(x, stats.beta.pdf(x, a, b), lw=2, color="gray", label=prior_label)
# Make the posterior values accessible and plot
df_trace_m1 = trace_m1.to_dataframe()
sns.kdeplot(df_trace_m1[("posterior", "p")], ax=ax1, color="blue", label="posterior")
ax1.set_title("Distribution of p")
ax1.set_xlabel("random variable x")
ax1.set_ylabel("PDF")
ax1.legend()
<matplotlib.legend.Legend at 0x7fb94274c190>
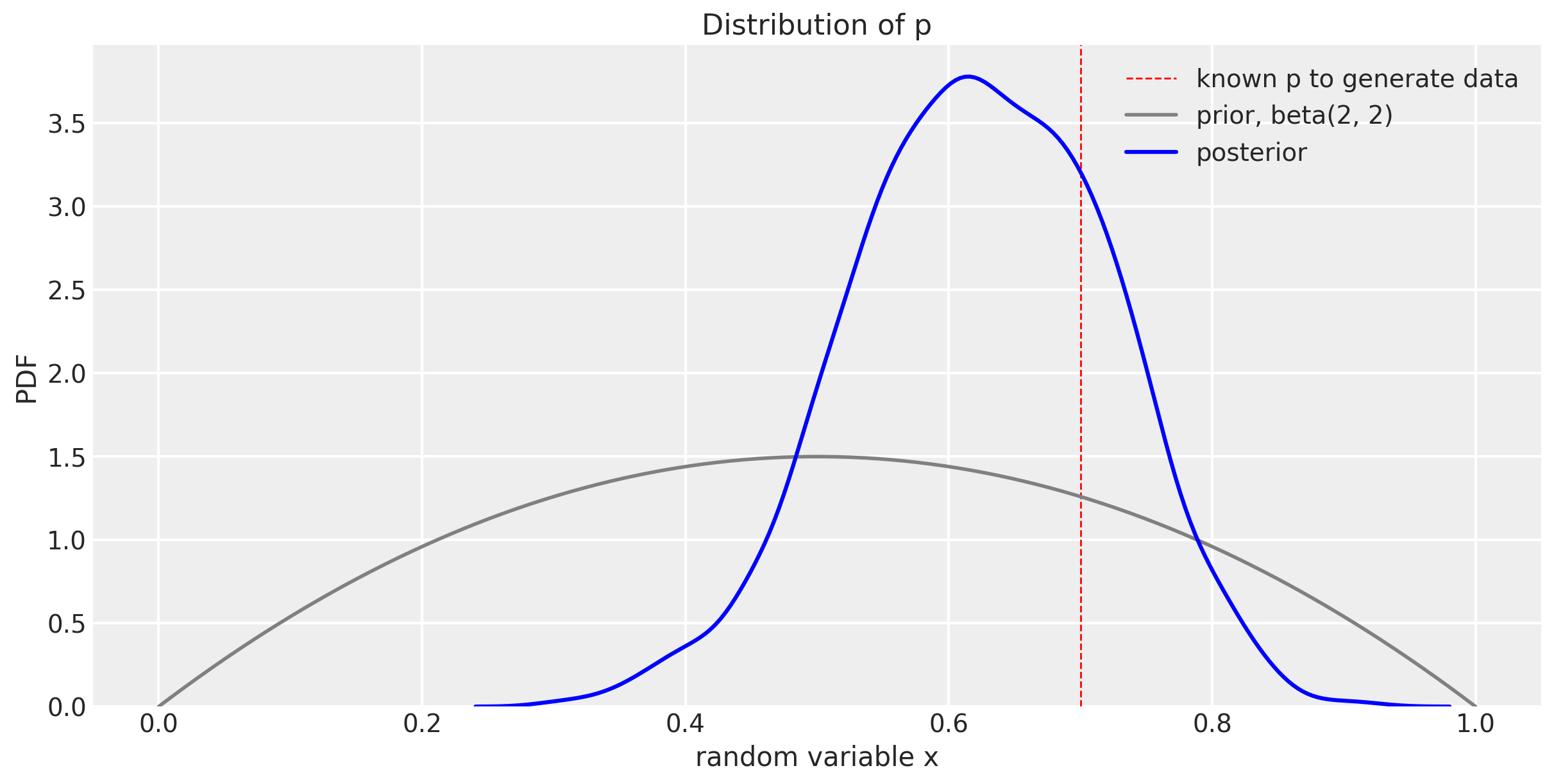
You can see how our distribution of $p$ narrows and gets closer to the known true value of 0.7, but hasn’t centered over the true value yet. This will happen with more trials. But more of the probability mass is around 0.7 than the prior was. We can look more specifically at the 89% compatibility interval like this.
az.summary(trace_m1)
| mean | sd | hdi_5.5% | hdi_94.5% | mcse_mean | mcse_sd | ess_mean | ess_sd | ess_bulk | ess_tail | r_hat | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| p | 0.623 | 0.097 | 0.474 | 0.778 | 0.002 | 0.002 | 1725.0 | 1714.0 | 1749.0 | 2869.0 | 1.0 |
Summary
In this post, we talked about running a model forwards and backwards. I used a simple binomial example to illustrate how a known parameter can be used to generate data (running forwards) and how using observed data can help us obtain plausible parameter values in the form of a distribution. You may know already that pymc (and other software) has built-in capability to produce prior and posterior predictive simulations. We’ll use this functionality in a later post.
Appendix: Environment and system parameters
%watermark -n -u -v -iv -w
Last updated: Mon Jan 03 2022
Python implementation: CPython
Python version : 3.8.6
IPython version : 7.20.0
json : 2.0.9
arviz : 0.11.1
pandas : 1.2.1
matplotlib : 3.3.4
pymc3 : 3.11.0
scipy : 1.6.0
seaborn : 0.11.1
numpy : 1.20.1
statsmodels: 0.12.2
Watermark: 2.1.0